Turning memorial comments into a Qlik word cloud
Context
I was a data analyst at Grupo Morada, a company in the funeral sector that offers funeral services and products, cemetery services, and assistance plans. One of our projects was Morada da Memoria, an online memorial with messages from family and friends. We wanted a fast way to see which words kept showing up so editors and managers could feel the tone of the stories.
Contexto
Eu era analista de dados no Grupo Morada, uma empresa do setor funerário que oferece serviços e produtos funerários, serviços de cemitério e planos de assistência. Um dos nossos projetos era o Morada da Memória, um memorial online com mensagens de familiares e amigos. Queríamos uma forma rápida de ver quais palavras mais apareciam para que editores e gestores pudessem sentir o tom das histórias.
Contexto
Yo era analista de datos en Grupo Morada, una empresa del sector funerario que ofrece servicios y productos funerarios, servicios de cementerio y planes de asistencia. Uno de nuestros proyectos era Morada da Memoria, un memorial online con mensajes de familiares y amigos. Queríamos una forma rápida de ver qué palabras aparecían más para que editores y responsables pudiesen captar el tono de las historias.
What I built
Inside the company we used Qlik as the main BI tool. We had recently moved from the old on-prem setup to Qlik’s cloud. Full-text search across fields and better insight features made it easy to poke at the data without a wall of SQL.
O que eu construí
Dentro da empresa usávamos o Qlik como principal ferramenta de BI. Tínhamos migrado recentemente da infraestrutura on-prem antiga para a nuvem do Qlik. A busca full-text nos campos e recursos melhores de insights facilitavam explorar os dados sem uma parede de SQL.
Lo que construí
Dentro de la empresa usábamos Qlik como herramienta principal de BI. Habíamos migrado recientemente de la infraestructura on-prem antigua a la nube de Qlik. La búsqueda de texto completo en los campos y las mejores funciones de insights facilitaban explorar los datos sin una muralla de SQL.
Plan:
- Pull memorial comments from MySQL
- Write a QVD for faster loads
- Split text into words
- Remove stopwords
- Count and visualize
Plano:
- Extrair os comentários do memorial do MySQL
- Gravar um QVD para carregamentos mais rápidos
- Dividir o texto em palavras
- Remover stopwords
- Contar e visualizar
Plan:
- Extraer los comentarios del memorial desde MySQL
- Escribir un QVD para cargas más rápidas
- Dividir el texto en palabras
- Eliminar stopwords
- Contar y visualizar
Data prep
After connecting to MySQL and exporting to a QVD, I loaded the data into the app.
Preparação dos dados
Depois de conectar ao MySQL e exportar para um QVD, carreguei os dados no app.
Preparación de los datos
Tras conectar a MySQL y exportar a un QVD, cargué los datos en la aplicación.
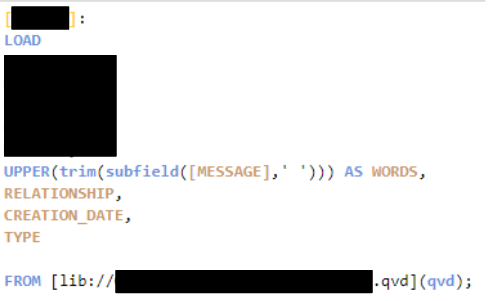
Tokenizing used SubField on spaces plus Trim to clean leftovers. Accents and punctuation get in the way, so I normalized case and stripped basic punctuation first. A small custom stopword list did most of the work.
A tokenização usou SubField nos espaços mais Trim para limpar resíduos. Acentos e pontuação atrapalham, então normalizei a caixa e removi a pontuação básica primeiro. Uma pequena lista personalizada de stopwords fez a maior parte do trabalho.
La tokenización usó SubField sobre los espacios más Trim para limpiar restos. Los acentos y la puntuación estorban, así que primero normalicé las mayúsculas y eliminé la puntuación básica. Una pequeña lista personalizada de stopwords hizo la mayor parte del trabajo.
// toy example of the idea
comments:
load
lower(purgechar(comment_text, '.,;:!?()[]{}"''')) as clean_text,
id
resident raw_comments;
// explode into one word per row
words:
load
id,
trim(subfield(clean_text, ' ', iterno())) as word
resident comments
while iterno() <= substrlen(clean_text);
// simple stopword table
stopwords:
load * inline [
word
and
of
the
a
an
de
da
do
e
];
// keep only words that are not stopwords and not empty
final_words:
left keep (words)
load word resident words where len(word) > 0;
anti join (final_words)
load word resident stopwords;To power the chart, the counting expression was a plain set analysis over the cleaned field:
Para alimentar o gráfico, a expressão de contagem era uma simples set analysis sobre o campo limpo:
Para alimentar el gráfico, la expresión de conteo era un simple set analysis sobre el campo limpio:
// count words excluding a maintained list
count({< word -= {'and','of','the','a','an','de','da','do','e'} >} word)Search and suggestions
Since early 2020, Qlik added stronger natural-language suggestions. That helped sanity-check the top terms and jump to the underlying stories when something odd popped up.
Busca e sugestões
Desde o início de 2020, o Qlik adicionou sugestões em linguagem natural mais robustas. Isso ajudou a validar os termos principais e ir direto para as histórias quando algo estranho aparecia.
Búsqueda y sugerencias
Desde principios de 2020, Qlik añadió sugerencias en lenguaje natural más potentes. Eso ayudó a validar los términos principales y saltar a las historias cuando algo raro aparecía.

What it looked like
I used a word cloud object to surface frequent words. It wasn’t meant to replace deeper analysis, just a quick read on themes and the language people chose in their tributes.
Como ficou
Usei um objeto de nuvem de palavras para destacar as palavras mais frequentes. Não era para substituir uma análise mais profunda, apenas uma leitura rápida sobre os temas e a linguagem que as pessoas escolhiam em suas homenagens.
Cómo quedó
Usé un objeto de nube de palabras para destacar las palabras más frecuentes. No pretendía sustituir un análisis más profundo, solo una lectura rápida sobre los temas y el lenguaje que la gente elegía en sus homenajes.

We also tucked a small sentiment view into the same dashboard. That helped the team notice shifts in tone over time and chase down outliers when needed.
That was the build: simple, fast to load, and useful in daily conversations as we planned to understand what people were mentioning so we could better understand the evolution process as the memorial grew.
Também incluímos uma pequena visualização de sentimento no mesmo dashboard. Isso ajudou a equipe a perceber mudanças de tom ao longo do tempo e investigar outliers quando necessário.
Foi isso: simples, rápido de carregar e útil nas conversas do dia a dia, já que planejávamos entender o que as pessoas mencionavam para compreender melhor o processo de evolução conforme o memorial crescia.
También incluimos una pequeña vista de sentimiento en el mismo dashboard. Eso ayudó al equipo a detectar cambios de tono a lo largo del tiempo e investigar valores atípicos cuando era necesario.
Eso fue todo: sencillo, rápido de cargar y útil en las conversaciones del día a día, ya que queríamos entender lo que la gente mencionaba para comprender mejor el proceso de evolución a medida que el memorial crecía.